This post describes step by step instructions on how to run WordCount program in Hadoop using Hortonworks virtual box. The prerequisites are virtual box application and sandbox_hdp_2.3_1 in the form of ova image which was explained in the other post in detail.
STEP 1
Open Oracle VM VirtualBox Manager and allocate a minimum of 4gb for hadoop in the settings. Then start the process by clicking start which is indicated by a green arrow mark.
click on the image to enlarge

STEP 2
After the virtual box has been started a console pop up and the processes for setting up hadoop in the machine continues for nearly 2 minutes.
click on the image to enlarge

After you can see the above image which indicates the hadoop has been set up on your machine, press if it is a windows machine, which gives you username and password to login to shell script
click on the image to enlarge

STEP 3
To view hortonworks GUI you have to go to this link http://127.0.0.1:8888/
click on the image to enlarge

To begin with shell script you have to go to this link http://127.0.0.1:4200/
click on the image to enlarge

STEP 4
So as the shell script appears you have to login with username: root and password : hadoop
Note : it may be sometimes the password you type is not visible but it works.
Then you have to make a directory with command mkdir
mkdir WCclasses
The first java files should be opened in any text editor and the codes should be copied
Then you have to upload the java programming files in the text editor with commandThe first java files should be opened in any text editor and the codes should be copied
click on the image to enlarge

You have to right click on the shell script and use option of paste from browser to paste the code. Then cross check whether the code has been pasted as such or any missing letters probably in the beginning of the code. Then press esc and use (:w) to save and (:q) to quit. And you are back from text editor.
click on the image to enlarge
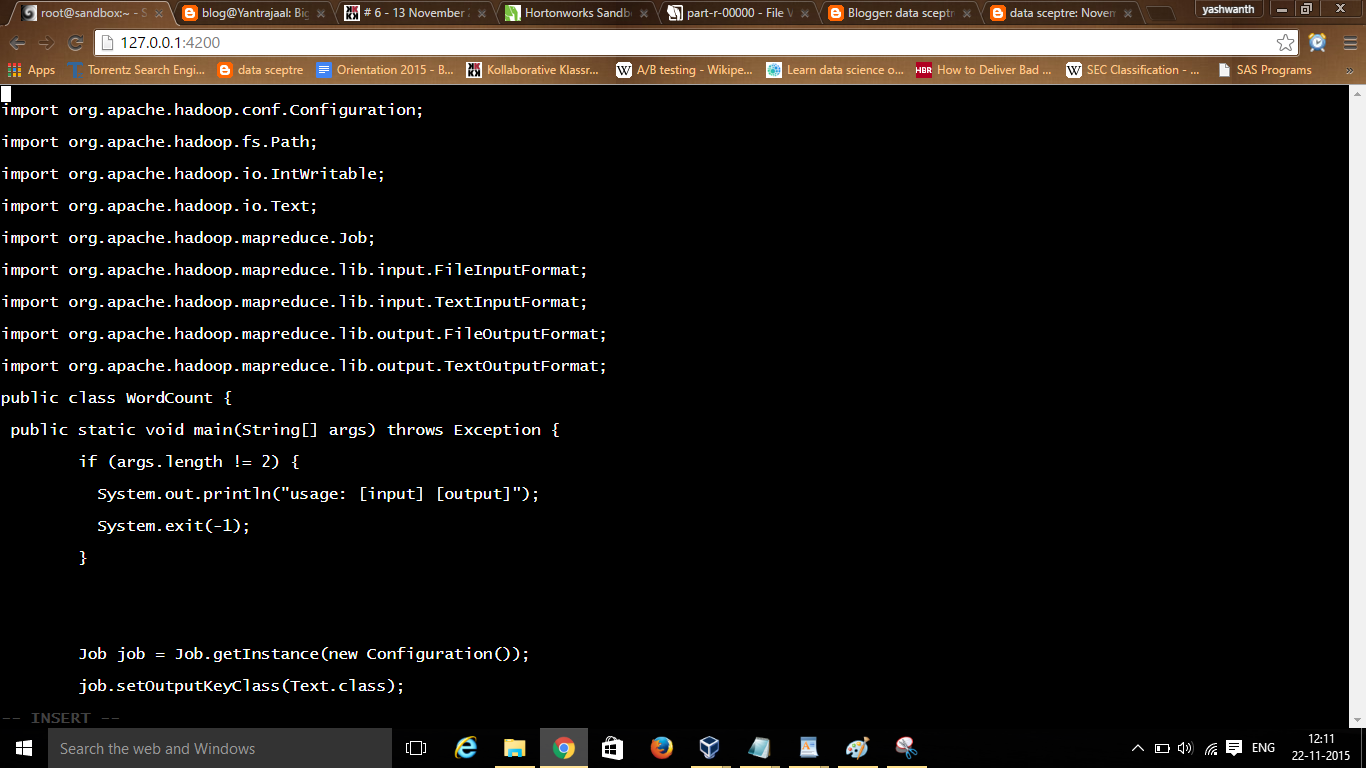
You have to follow same procedure for the other two files one by one( use vi WordMapper.java and SumResucer.java, then paste the codes copied and save and then quit).
STEP 5
After uploading all the java programming files now you have to compile by using the following codes one by one
javac -classpath /usr/hdp/2.3.0.0-2557/hadoop/hadoop-common-2.7.1.2.3.0.0-2557.jar:/usr/hdp/2.3.0.0-2557/hadoop-mapreduce/hadoop-mapreduce-client-core-2.7.1.2.3.0.0-2557.jar:/usr/hdp/2.3.0.0-2557/hadoop-mapreduce/commons-cli-1.2.jar: -d WCclasses WordCount.java
javac -classpath /usr/hdp/2.3.0.0-2557/hadoop/hadoop-common-2.7.1.2.3.0.0-2557.jar:/usr/hdp/2.3.0.0-2557/hadoop-mapreduce/hadoop-mapreduce-client-core-2.7.1.2.3.0.0-2557.jar:/usr/hdp/2.3.0.0-2557/hadoop-mapreduce/commons-cli-1.2.jar -d WCclasses WordMapper.java
javac -classpath /usr/hdp/2.3.0.0-2557/hadoop/hadoop-common-2.7.1.2.3.0.0-2557.jar:/usr/hdp/2.3.0.0-2557/hadoop-mapreduce/hadoop-mapreduce-client-core-2.7.1.2.3.0.0-2557.jar:/usr/hdp/2.3.0.0-2557/hadoop-mapreduce/commons-cli-1.2.jar -d WCclasses SumReducer.java
javac -classpath /usr/hdp/2.3.0.0-2557/hadoop/hadoop-common-2.7.1.2.3.0.0-2557.jar:/usr/hdp/2.3.0.0-2557/hadoop-mapreduce/hadoop-mapreduce-client-core-2.7.1.2.3.0.0-2557.jar:/usr/hdp/2.3.0.0-2557/hadoop-mapreduce/commons-cli-1.2.jar -d WCclasses WordMapper.java
javac -classpath /usr/hdp/2.3.0.0-2557/hadoop/hadoop-common-2.7.1.2.3.0.0-2557.jar:/usr/hdp/2.3.0.0-2557/hadoop-mapreduce/hadoop-mapreduce-client-core-2.7.1.2.3.0.0-2557.jar:/usr/hdp/2.3.0.0-2557/hadoop-mapreduce/commons-cli-1.2.jar -d WCclasses SumReducer.java
If you do not get any message and the underscore moves to next line it means that the code is good and it is compiled. If it gives any message then code should be properly checked before pasting and after pasting.
STEP 6
Once you are done with compilation, you should use jar command to give a jar file.
jar -cvf WordCount.jar -C WCclasses/ .
It should give the similar outputclick on the image to enlarge

Now you should use the output command to yield the output
hadoop jar WordCount.jar WordCount /user/hue/wc-inp /user/hue/wc-out6
the number out6 indicates number of times the output has been produced so i'm using 6 because I have runned the output 5 times previously, you can use starting with out1 if it is first time.
The output should be similar. In the end it should "the url to track the job". If it appears that means it is successfully submitted and our work with shell script has been completed. Now its time to move to eye candy GUI part.
STEP 7
Let the console be like that and go to the link http://127.0.0.1:8088/cluster to view the ongoing process. And after it has been completed(keep on refreshing) go to the link http://127.0.0.1:8000/about/ and in the icons click on the file browser which should lead you to window like this
click on the image to enlarge

Then click on the output you have given and click on the "part r-00000" to view output.
click on the images to enlarge


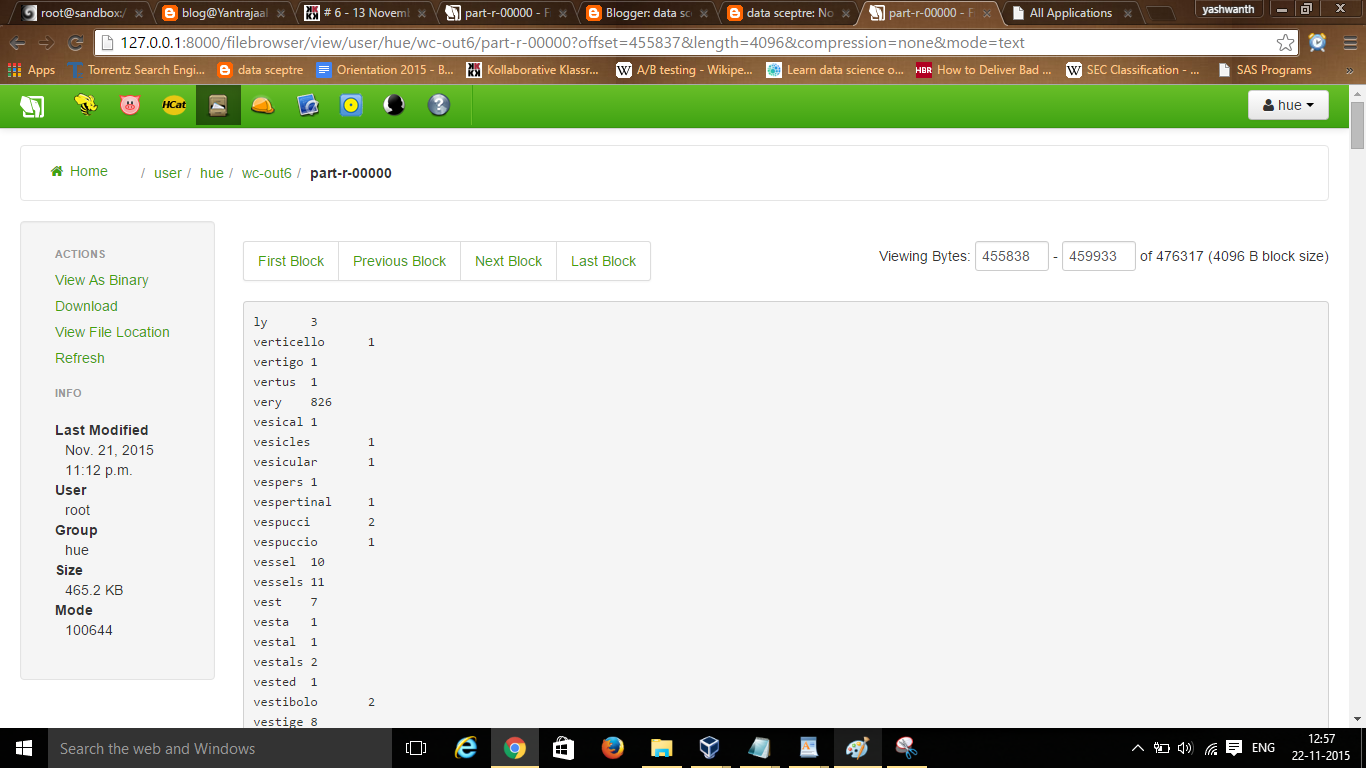
The presented above is the output showing each word count (frequency) in the books.
seen
ReplyDelete