What is Hive?
Hive is a component of Hortonworks Data Platform(HDP). Hive provides a SQL-like interface to data stored in HDP.Hive provides a database query interface to Apache Hadoop.People often ask why do Pig and Hive exist when they seem to do much of the same thing. Hive because of its SQL like query language is often used as the interface to an Apache Hadoop based data warehouse. Hive is considered friendlier and more familiar to users who are used to using SQL for querying data. Pig fits in through its data flow strengths where it takes on the tasks of bringing data into Apache Hadoop and working with it to get it into the form for querying. A good overview of how this works is in Alan Gates posting on the Yahoo Developer blog titled Pig and Hive at Yahoo! From a technical point of view both Pig and Hive are feature complete so you can do tasks in either tool. However you will find one tool or the other will be preferred by the different groups that have to use Apache Hadoop. The good part is they have a choice and both tools work together.
Task
We are going to find the player with the highest runs for each year. This file has all the statistics from 1871–2011 and contains more that 90,000 rows. Once we have the highest runs we will extend the script to translate a player id field into the first and last names of the players.
The files downloading and uploading has already been done (refer previous program for process).
After starting hadoop environment we can go to the link 127.0.0.1:8000 which displays a web page as follows.(Click on the images to enlarge)

Then we can go to the file browser by clicking the icon in the header bar to see the files uploaded.






After starting hadoop environment we can go to the link 127.0.0.1:8000 which displays a web page as follows.(Click on the images to enlarge)

Then we can go to the file browser by clicking the icon in the header bar to see the files uploaded.

We can click on the second icon in the header bar to go to hive ui environment. We get directed to query editor where we can write, edit and execute code.( Note: In hive query editor we should execute one query at a time: for next query we should erase previous query and write a new one, not below it)
STEP 1:
Create table called temp_batting
create table temp_batting (col_value STRING);

After writing query we should execute it by clicking execute in the footer. To check whether the table has been created click on the table in the second header bar.

To view table select table and click on the view icon as it is empty table we will not find any values.

STEP 2:
We load data into the hive environment by giving in path query as
LOAD DATA INPATH '/user/admin/Batting.csv' OVERWRITE INTO TABLE temp_batting;

STEP 3:
To view the data whether it is loaded properly we can use select command as
SELECT * FROM temp_batting LIMIT 100;

It gives results as

STEP 4:
We create another table batting with "player_id, year and runs"
create table batting (player_id STRING, year INT, runs INT);

We can view the table created by clicking view as we did previously


Then it takes sometimes to run the query




STEP 5:
Now we select year and max runs from table batting and group it by year
SELECT year, max(runs) FROM batting GROUP BY year;

It gives results as

We can scroll down and even to next page at the end of page

STEP 6:
To get names of players we use join as


SELECT a.year, a.player_id, a.runs from batting a
JOIN (SELECT year, max(runs) runs FROM batting GROUP BY year ) b
ON (a.year = b.year AND a.runs = b.runs) ;
JOIN (SELECT year, max(runs) runs FROM batting GROUP BY year ) b
ON (a.year = b.year AND a.runs = b.runs) ;

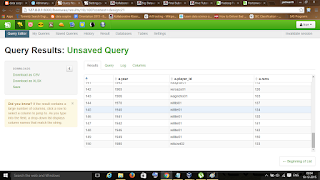
The results will be


This makes end of program with desired results (pretty simple and interesting I guess :) )